

Read the latest on our research, technology, products and services.
Featured Content
SMPL: A Skinned Multi-Person Linear Model
Our Skinned Multi-Person Linear model (SMPL) is a skinned vertex-based model that accurately represents a wide variety of body shapes in natural human poses. The parameters of the model are learned from data including the rest pose template, blend weights, pose-dependent blend shapes, identity-dependent blend shapes, and a regressor from vertices to joint locations.

Continue Reading

We demonstrate a new approach called MoSh (Motion and Shape capture), that automatically extracts this detail from mocap data. MoSh estimates body shape and pose together using sparse marker data by exploiting a parametric model of the human body.

We accurately estimate the 3D geometry and appearance of the human body from a monocular RGB-D sequence of a user moving freely in front of the sensor. Range data in each frame is first brought into alignment with a multi-resolution 3D body model in a coarse-to-fine process.

To look human, digital full-body avatars need to have soft-tissue deformations like those of real people. Download this free research paper from Max Planck Institute for Intelligent Systems to understand how they built a model with soft-tissue deformations from examples using a high-resolution 4D capture system and a method that accurately registers a template mesh to sequences of 3D scans.
Our Skinned Multi-Person Linear model (SMPL) is a skinned vertex-based model that accurately represents a wide variety of body shapes in natural human poses. The parameters of the model are learned from data including the rest pose template, blend weights, pose-dependent blend shapes, identity-dependent blend shapes, and a regressor from vertices to joint locations.

We define a new dataset called FAUST that contains 300 scans of 10 people in a wide range of poses together with an evaluation methodology. To achieve accurate registration, we paint the subjects with high-frequency textures and use an extensive validation process to ensure accurate ground truth.

We describe a solution to the challenging problem of estimating human body shape from a single photograph or painting. Our approach computes shape and pose parameters of a 3D human body model directly from monocular image cues and advances the state of the art in several directions.

We estimate 2D human pose from video using only optical flow. The key insight is that dense optical flow can provide information about 2D body pose. Like range data, flow is largely invariant to appearance but unlike depth it can be directly computed from monocular video.
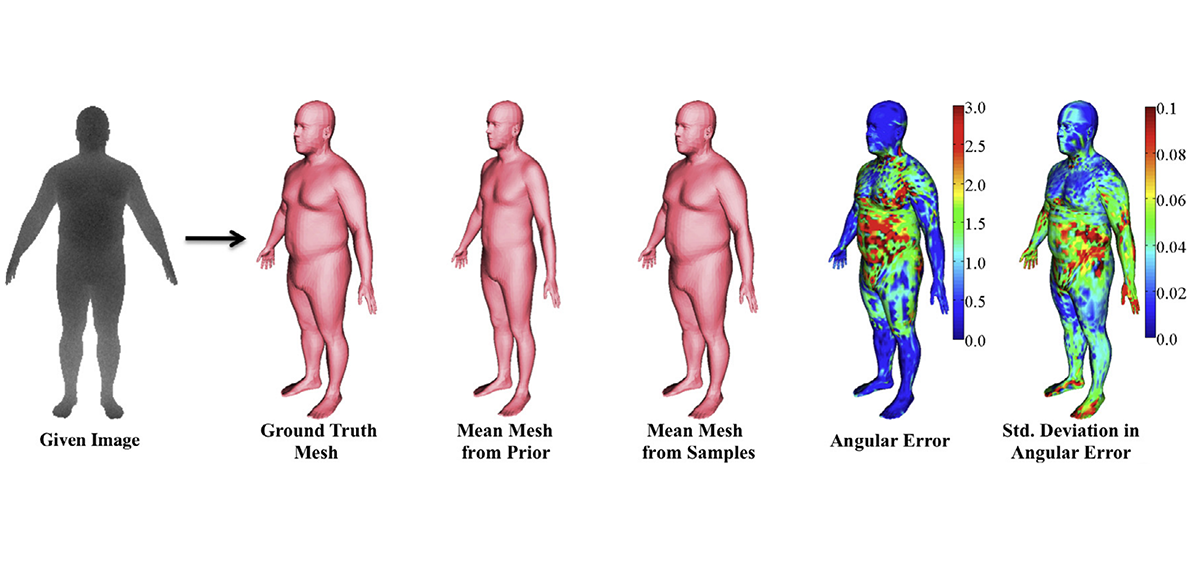
The informed sampler, using simple discriminative proposals based on existing computer vision technology achieves dramatic improvements in inference. Our approach enables a new richness in generative models that was out of reach with existing inference technology.

Built on a new auto differentiation package and OpenGL, OpenDR provides a local optimization method that can be incorporated into probabilistic programming frameworks. We demonstrate the power and simplicity of programming with OpenDR by using it to solve the problem of estimating human body shape from Kinect depth and RGB data.
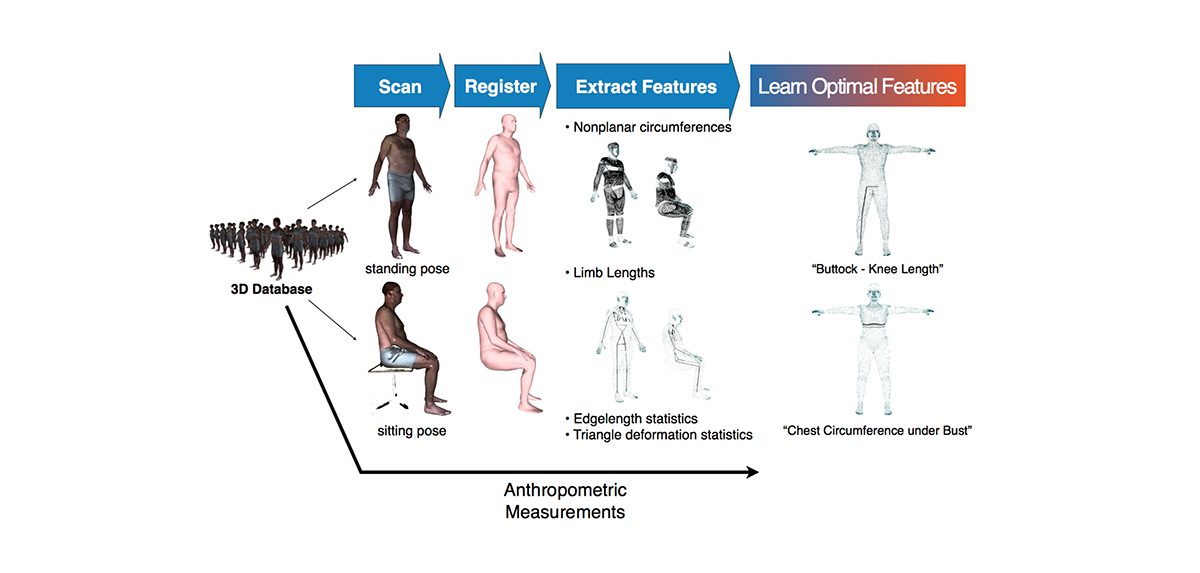
Learn mapping from these features to measurements using regularized linear regression. We perform an extensive evaluation using the CAESAR dataset and demonstrate that the accuracy of our method outperforms state-of-the-art methods.

We propose a simple method to estimate standard body measurements from the recovered SCAPE model and show that the accuracy of our method is competitive with commercial body scanning systems costing orders of magnitude more.
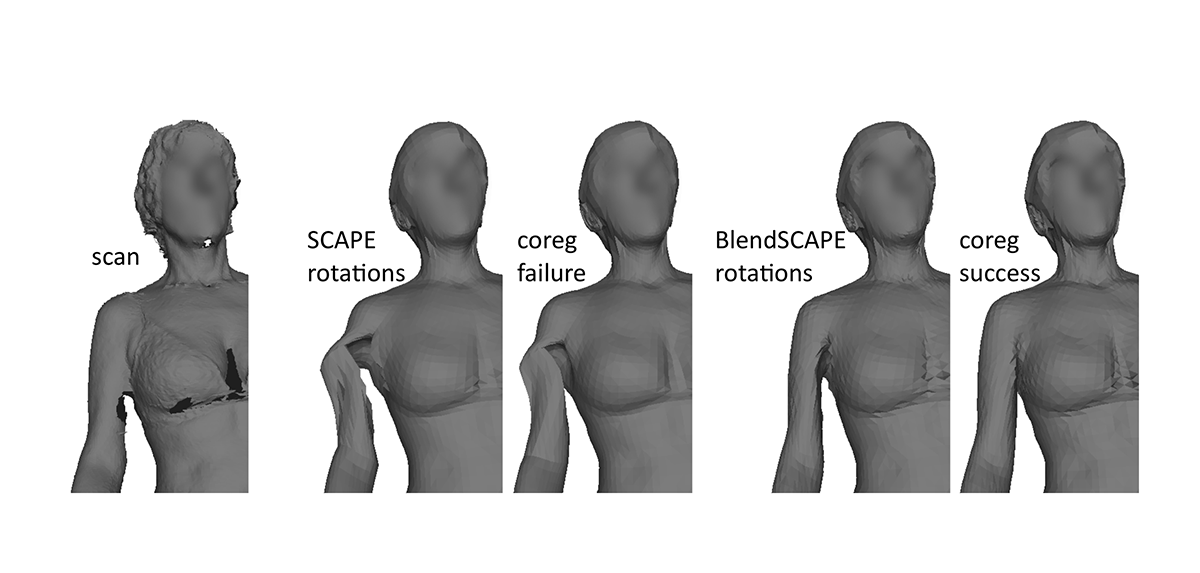
By minimizing a single objective function, we reliably obtain high-quality registration of noisy, incomplete, laser scans, while simultaneously learning a highly realistic articulated body model. The model greatly improves robustness to noise and missing data. Since the model explains a corpus of body scans, it captures how body shape varies across people and poses.

By placing a matrix normal-inverse-Wishart prior on these affine transformations, we develop a ddCRP Gibbs sampler which tractably marginalizes over transformation uncertainty. Analyzing a dataset of humans captured in dozens of poses, we infer parts which provide quantitatively better deformation predictions than conventional clustering methods.
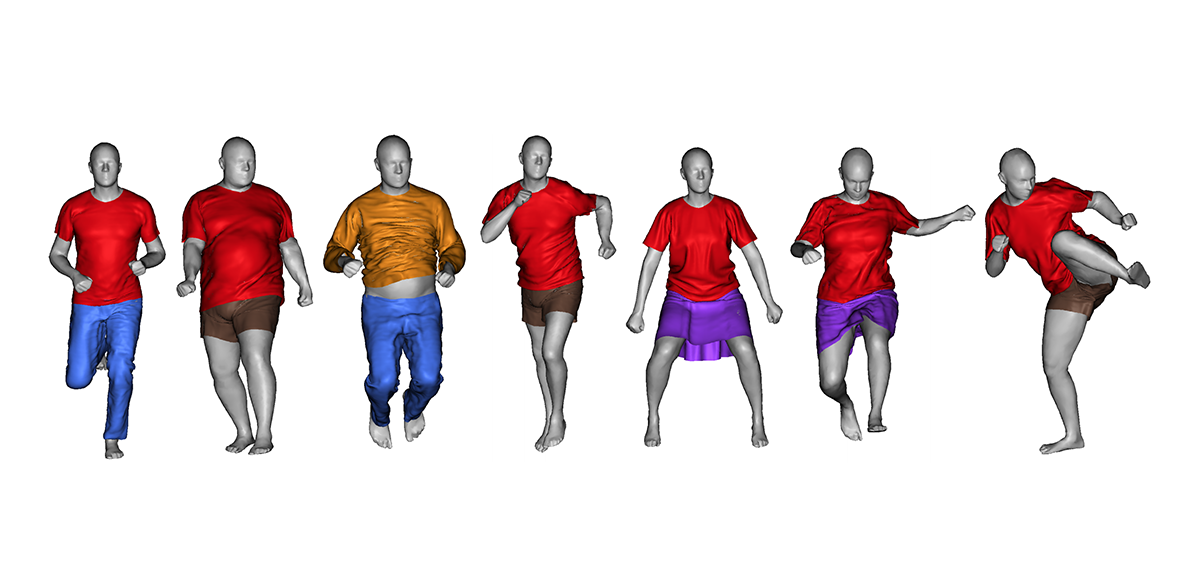
DRAPE can be used to dress static bodies or animated sequences with a learned model of the cloth dynamics. Since the method is fully automated, it is appropriate for dressing large numbers of virtual characters of varying shape. The method is significantly more efficient than physical simulation.

With Body Labs, you can now easily repose, resize and animate characters inside of Maya® on the fly. Body Labs uses AI — trained on thousands of scans of real human body shapes and poses — to empower you to instantly recompute corrective blend shapes tied directly to the joint angle of the skeletal rig.

Returns, along with out-of-stocks and overstocks, have been referred to as the “Ghost Economy” by IHL Group. To address these challenges, Body Labs set out to explore the reasons behind returns to identify what contributes to problems with apparel and footwear fit through a consumer survey of U.S. online and offline shoppers.

Body Labs Blue delivers the perfect fit for your customers by taking just height and weight to produce 17 accurate measurements. To help ensure accuracy your customers can also refine six key measurements predicted by Blue to accurately produce 11 additional measurements ideal for custom clothing.